江荻 龙从军|中国民族语言大规模标注文本的检索技术实现及其价值
2024-11-10 23:56


江荻,男,湖南长沙人,江苏师范大学特聘教授,中国社会科学院研究员,研究方向为汉藏语言学、民族语文信息处理。龙从军,男,四川通江人,中国社会科学院研究员,主要研究方向为语料库语言学、计算语言学。
民族语言属于低资源语言,随着社会经济的发展,其越来越成为一种稀缺资源。然而语言是文化的传承载体,多样的民族语言承载了多样的文化类型。珍贵的民族语双语对译文本数据为民族语言文化传承保护和跨学科研究提供了丰富的素材。中华人民共和国成立以来,我国学者发表了大批民族语言研究成果,包括研究论文、个人专著、系列丛书和辞书。《民族语文》是刊发民族语言研究成果的主要阵地。自1979年创刊到2023年3月刊发文章3528篇。一些大学学报、语言学期刊、论文集、零星出版的个人专著以及系列丛书是民族语言数据的重要来源。尤其需要强调的是民族语言学界5套规模宏大的丛书,分别是《中国少数民族语言简志》丛书(57部)、《新发现语言研究》丛书(48部)、《中国濒危语言志》少数民族语言系列丛书(20部)、《中国少数民族语言参考语法研究系列丛书》(13部)和《中国少数民族语言系列词典丛书》(23种)。这些纸质出版物中的数据大体都采用了隔行对译方法,以民族语言和国家通用文字隔行对译的方式呈现。然而,由于受民族语言文本自身特点以及民族语言信息技术发展缓慢和研究群体规模小等的条件限制,当前对这些大规模数据进行整理,制作成语料库,实现自由检索还存在较大困难。尤其是20世纪中后期大量民族语言专业文本以纸质形式出版,后来有了PDF电子版,但是还未能满足智慧检索和二次开发条件。2015年开始实施的“中国语言保护工程”项目,实行按照隔行对照模式标注和存储民族语言数据,具备了进一步开发应用的基础。但到目前为止,长篇语料的隔行标注文本还未见在线发布。可见,以国际音标为转写形式的在线检索的民族语言标注文本数据资源十分缺乏。随着信息技术的发展,一些有传统文字文献的民族语言在线隔行标注文本资源建设有一定的进展。例如龙从军等发布系列藏文古文献隔行对照标注语料库,该语料库包括吐蕃时期的藏文金铭石刻27件文献、《拔协》《韦协》《柱间史》《底吾史记》等著名典籍的全文隔行标注语料。在国际上,人类学和民族语言学者一直提倡和践行民族语言隔行标注语料的制作和使用。一些非营利的社会组织以在线形式,开展全世界民族语言资源积累,其中也有一部分隔行标注文本,如SIL International(SIL)长期致力于世界上民族语言数据的收集、整理和研究,马克斯·普朗克人类认知和神经科学研究所为了给语言学家和研究人员提供各种语言学数据的资源库,主持了The Language Archive(TLA)和The Endangered Languages Project等项目,这些研究促进了民族语言隔行标注文本制作,但是收录的语种数量和文本规模还非常有限,尤其是涉及我国境内民族语言的标注文本就更少了。互联网技术改变了人们获取资源的方式,“加快数字化发展,建设数字中国是国家信息化战略的重要组成部分”,检索数据资源成为专家学者和普通使用者的一种期盼。结构化在线语言数据又是基于大数据分析、人工智能的基础,传统纸质载体的民族语言数据逐渐会通过数字人文技术实现电子化和文本化。把具有规范化、标准化的民族语言标注文本实现在线检索,会对民族语言研究有极大的推动作用。由中国社会科学院民族学与人类学研究所主持完成的《中国民族语言语法标注文本》丛书,以呈现长篇语料为核心,通过国际音标转写原文,并按照原文行、标注行、翻译行3行对照的形式,对藏、彝、哈尼、纳西、土家、白、壮、黎、水、维吾尔、佤、独龙等民族的传统口传故事、族群起源传说、日常口语对话、儿童或寓言故事文本进行了语法标注。这种语料处理范式对语言类型学、历史语言学、区域语言学、语言接触研究等资源依赖型学科有重要的价值,也为从事民族学、人类学、历史学和自然语言处理的学者提供必备的资源。该丛书目前已出版两集20部,其作为小语种低资源真实文本语料具有重要的研究价值和应用价值,且规模已达千万字数以上,引起了国内外广泛重视。但纸质版的语言资源是一种静态资源,以著作形态呈现,无法提供数据自由索引,不能实现文本多功能动态检索和统计,因此实际使用效率较低。为解决这样的现实问题,国家社会科学基金规划办组织专家开展论证,同意设立相应选题破解这样的难题,使珍稀的民族语言文化资源面向学术和社会,为更广泛的语言知识、语言认知、语言教学、语言文化认同和语言信息处理等学科提供优质服务。本文着重讨论这部分资源的应用技术实现问题。
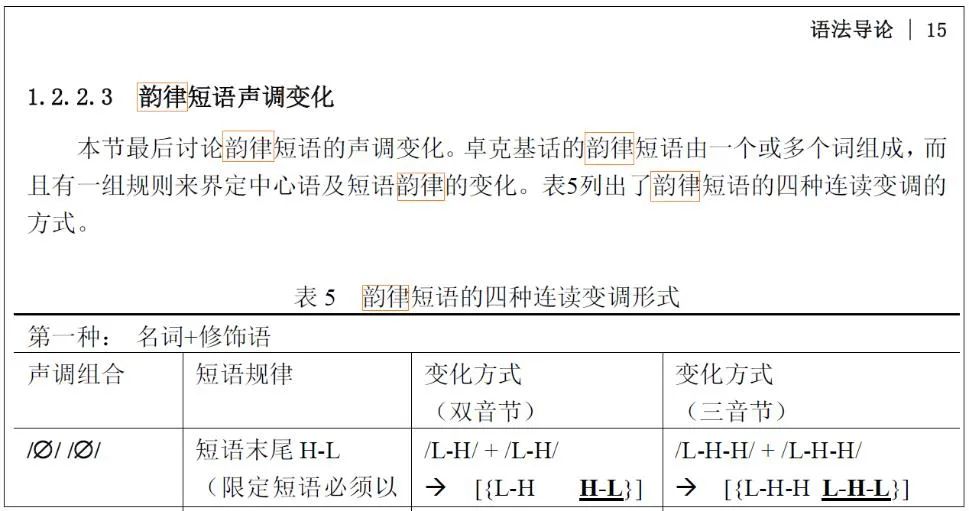
《中国民族语言语法标注文本》丛书于2010年获中国社会科学院重大课题立项,2012年获国家社会科学基金重大招标课题支持,先后入选2015年度(第一批)和2019年度(第二批)国家出版基金资助项目,并被列为“十二五”“十三五”国家重点图书出版规划项目。参与该项目科研人员30余人,涉及国内侗台、苗瑶、藏缅、南亚、阿尔泰等多个语系语族语言和方言,目前已出版20部,具体是:藏语拉萨话、土家语龙山话、哈尼语绿春话、白语大理话、藏语甘孜话、嘉戎语卓克基话、壮语武鸣话、纳木兹语木里话、水语苗草话、维吾尔语乌鲁木齐话、哈尼语窝尼话、义都语西巴话、达让语察隅话、多续语冕宁话、藏语噶尔话、彝语凉山话、独龙语孔当话、纳西语大研镇话、黎语白沙话、佤语岩帅话,总字数约为1000万字。该丛书的编撰思想和学术价值是多方面的,这是中华人民共和国成立以来第一次以大规模真实文本方式开展的语言调查研究,相当程度上改变了数十年形成的语言调查和语法研究模式。按照项目设计方案,文本丛书的具体内容包括民间传统口传故事、族群起源神话传说、儿童或寓言故事、日常口语对话等。这些文本资源一方面有相当高的口语性和真实性,同时也具有一定的文化积累性和相应的文学水平,是相当难得的民族性、文学性文化资源,对于从事民族学、社会学、人类学、历史学、语言学和其他学术研究的学者都有重要参考价值。而项目记录形式对语言学本体研究也十分重要,一是涉及语言广泛,二是采用了国际通行的小语种隔行对照化标注文本模式,其目的是为民族语言研究和创建中国语言理论提供丰富的基础材料。丛书的学术价值和特征主要体现在以下3个方面。1. 以标注文本为核心的创新范式。中国民族语言领域内,以往传统观念总是把记录语料作为语法著作的附录,数量少且处于附属地位。这套丛书直接将标注文本作为正文主体,语音、词汇和语法导论作为阅读文本标注体系的参考。这样的设计甚至比时兴的“参考语法”更为超前,目的就是让语言概况或语法导论服务于大规模语法标注资源,接受真实文本资源的测试和检验。这种创新研制思路开拓了语言研究的新方向,跟学界倡导的记录语言学不谋而合。更具价值的是,丛书作者所采录的文本大多来自田野调查,或来自民间记录故事,与以往的例句翻译式调查或诱导式例句调查相比,这样的语料从本源上避免了主观性,甚至杜绝了母语人自身的内省式语法案例。从方法论上看,如果以真实文本为语料的研究能推动学术界重视和形成描写语言研究范式,这样的创新是非常有价值的。2. 以基本语法结构为基础标准的依据。建立语法描写的基本标准,这是基于项目为语言专题深度研究提供支撑的服务理念设计。我们从三方面加以说明。首先,我们认为新近发展的一些语言分支学科具有资源依赖性质,例如语言类型学一般是跨语言或跨方言的,语言接触研究也需要双语或多语资源的支持。对于无文字语言,它们的语法化或词汇化研究更需要亲属语言的相互印证。至于机器翻译也一定是在双语或多语语料相互对照条件下才能开展起来的。其次,丛书包含藏缅语言、侗台语言、苗瑶语言、南亚语言以及阿尔泰语言,类型差异很大,譬如有的语言是SVO语序,有的则是SOV语序;有的是前置词系统,而有的则是后置词(词格)系统等等。特别是目前各语言研究的广度和深度差异较大,采纳的理论和研究的方法也不完全相同,为此,确定一个简洁的基本结构方法或描写方法对文本进行基础语法标注是合适的。其三,学有所长,术有专攻。真正利用这套丛书语料的学者未必熟悉各种语言,更不可能很快掌握这些陌生语言的语法体系,要求每个学者都调查多种语言、掌握多种语言并不现实,也没必要。在这个意义上,我们组织专业人员开发可供其他学者开展专题深入研究的文本资源,特别是熟语语料语法标注文本就非常有价值。显然,从以上叙述可以看出,基础标注就是无论某语言是何种类型,无论某语言研究的深度如何,这套丛书都以基本语法结构框架来标注各种语言的词法形态和句法现象,例如“性、数、格、时、体、态”范畴,同时标上通用语对译词语。值得提示的是,这套丛书的作者都是各自民族语言领域的专家,他们对语言的结构描写和基础标注为读者提供了一个了解该语言的高起点平台。3. 适用于真实文本资源的科学体系。丛书具体处理方法上采用了两种可行技术,一是国际小语种通行的隔行对照(Interlinearization),即将民族语(小语种)跟通用语(如汉语或英语)分行书写,同时又使两种语言的词语和语法符号之间分行对齐。这种方法是目前世界各国学者研究少数族群语言的主流方法,通过隔行对照化形成一种语言学家或语言学专业研究生都能读懂的文本,即三行一体隔行对照化文本。例如嘉戎语(本例有韵律行,某些语言可能有文字行):
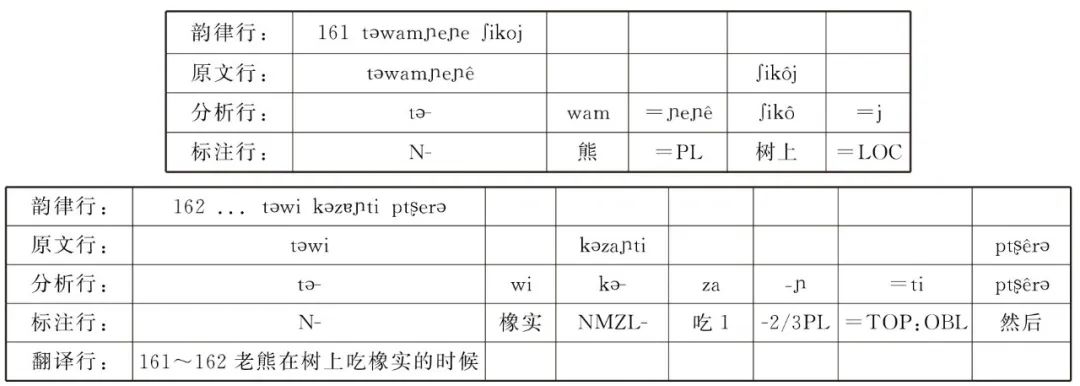
观察上述嘉戎语例句可知,韵律行包括轻重音、声调或句调、停顿和延长等韵律要素,分析行可能将词根、前后词缀等切分出来呈现,标注行则采用通语文字和语法标注符号逐词逐符对分析行进行标注,翻译行是全句的直译,有时会包括多个韵律行短语小句。语言学是世界通行的一门学术领域和体系,语言学研究水平表征着一个国家科学研究的软实力。如果中国语言资源能获得广泛应用,成为学术界和社会各界的公共产品,则必定推动中国语言学的进步和发展,也凸显出这类资源的价值和作用。这个目标是我们推进本项目资源检索应用的主要动力。
ntent="t">二、资源存储形式和检索技术思路
《中国民族语言语法标注文本》丛书采用统一书稿体例,每册内容分3个部分:语法导论、文本标注和索引词表。考虑到文本标注是隔行对照形式,虽然这3部分的内容和格式可分别采用不同检索策略,但在保持输出风格一致基础上,主要检索结果都将是基于Lucene原理(全文检索引擎框架)的TXT与相应PDF(非结构化数据)双文本全文检索技术,即对TXT文本建立索引,又通过将TXT文本检索实现为PDF显示输出方式。图1呈现了本文数据采录、存储、分析和输出展示功能框架。数据库部分用于存储语法标注文本中的语料资源,包括原始语料资源的处理过程以及存储方式,也是整体框架里的数据录入部分。数据分析部分则主要用于对存储在数据库内的数据进行分析,由于后续需要不断扩充此部分的功能,所以采用模块化的方法,并且提供相应的数据接口,供数据平台调用。而用户交互部分则可以理解为用户所看到的界面。另外我们还会单独设计一个数据展示平台,在该部分中,灵活性和可扩展性是我们主要考虑的问题。该部分主要用于显示检索到的数据内容,同时对检索到的内容进行分析并将分析结果以可视化的方式展示出来。
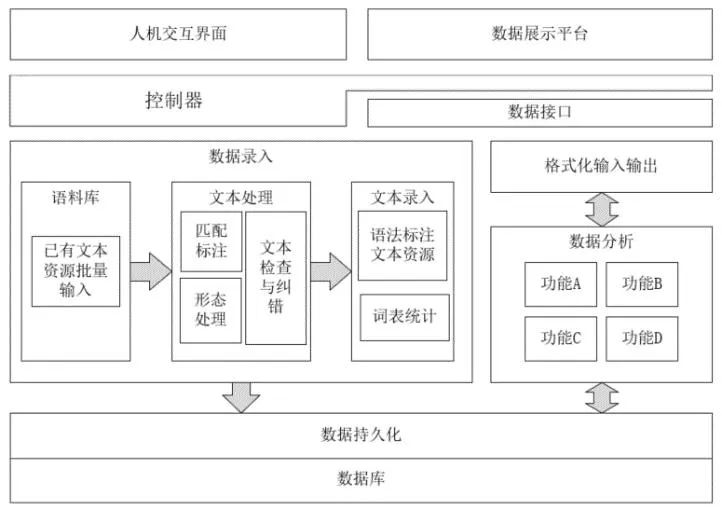
图1 线上系统整体框架
按照丛书统一的存储方式,也可以按照具体内容来叙述文本的检索方法。检索结果以检索词的高亮方式显示。1.语法知识检索。该检索针对“语法导论”部分,检索输入内容是通用语的语音、词汇、形态和语法术语,也可以是语法范畴或者语法特征标记符号,例如“ASP”表示“体”范畴。也可以通过二级词汇术语精准检索,例如“第三人称\单数”(3\sg),或者“ASP\PEF”(体\已行体)。输出结果一般是包含“语法导论”中该检索词条的文本行以及前后若干行文本。例如查找“韵律”得到数条结果:
2. 词表检索。每部标注文本都带有该语言所用民汉双语对照词汇表(民汉指民族语言和汉语),检索设计上一般采用精确检索方式,可以直接用汉语或者民族语言(音标形式或文字的转写形式)进行检索,输出包含被检索项所在页码的原书PDF文本双语对照词汇表。3. 文本注释词语和语法特征检索。该部分内容是项目最主要的研究对象。设置三类检索对象:通语注释词语(汉语)、语法特征或语法标注符号、民族语言词形(音标或转写形式)。输出部分则是包含被检索项所在页码的整页隔行对照化标注文本。4. 浏览检索。系统列出原书目录,允许点击直接切入目录内容页码处,然后上下翻页浏览前后3~5页内容。该项功能也适用于知识检索、词表检索和文本语法特征检索,即在检索所达页面上下翻页浏览。浏览检索能使用户在一定篇幅内阅读连续文本,扩大信息获取范围。采用双文本检索和输出虽然是技术实现上的需求,但也有一定的语用需求因素。换句话说,对整体纸质版形式文献进行检索在一定程度上受到原件的应用心理制约。纸质版资源呈现的格式给使用者留下了稳定可靠的心理印象,是格式不变且可以信赖的资源查验标准。为此,资源的这种存储形式使检索设计者不得不满足用户可能存在的这种心理,也就是既要能够检索还要能够与原版文献对照。根据这样的要求,检索结果必然以原版文献形式呈现。例如嘉戎语文献中检索POSS(领属格标记),呈现的原文如下:
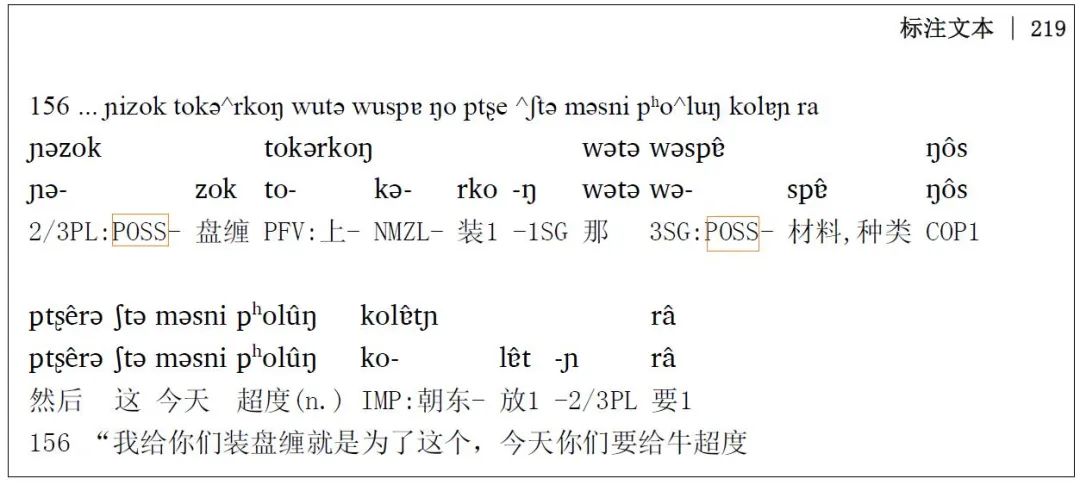
检索结果与书稿文献保持着一致性,满足了用户对资源提取可靠性的要求,也释放了用户核对原文的压力。这样的设计思路具有较高的人文关怀和友好意图。
依据需求设计思路,项目在检索处设置了资源范围和检索域。资源范围以20部专著目录列表作为选择对象,一次可以选择一种或多种专著资源,也就是多种语言,通过点击目录实现选择。检索域指著作资源的三大板块:语法知识检索、词表检索、文本和标注检索。检索域的区分实际是为了实现快速指向和精准检索,避免三大板块检索词的相互干扰。同时,由于原著检索域格式的差异,分域检索有利于检索结果的呈现。检索结果以提示方式初步呈现,用户可进入〈快速预览〉直接查看包含该资源的原文形式,也可进入〈查看原文〉浏览该检索项所在原文页码及其上下多页内容(截图略)。

检索结果为用户提供了接近于翻阅原书、同时又具备高度信息化功能的阅读体验。展示页面允许用户缩放原书,位图形成的页面使原书在高度放大后也不会模糊;在展示中可以针对页面文本进行二次查找、标记、注释,在注册权限通过的情况下,原文内容也可以被选中和拷贝。最后还可以提到,查看原文实际上也实现了模糊检索和上下文检索的主要功能。后台的系统数据入库时,会将数据按照分页、分句、分词的粒度逐步处理。分页保障了用户能够根据关键字或指定数目找到与原书完全一致的页面。分句一方面是分词的基础,同时也是预览页面展示的内容。分词将原文拆成最小粒度的词汇,在经过停用词处理后,选择有意义、有价值、值得检索的词汇存入数据库,同时也保存分句与页面信息,以便关键词检索时使用。为实现目标,数据库设计方面,我们舍弃了传统的按照对象层级存储信息的方式,选择了扁平化的数据结构,即关键字、词语统计、语法标注、所在分句、书名、原书页码等信息压缩在一个表中存储。这样的数据表具有非常多的行数,但由于有效信息储存在同一个记录(Entry)中,因此减少了数据库检索次数,主键的规律性使一次性快速检索的速度和成功率相当之高。
本检索系统提供常用的统计信息,包括每本书标注文本部分的词频、语法标记符号的频次。标注文本采用了隔行对照形式,包括原文行、分析行、标注行和意译行,同时在每个隔行标注故事之后还提供了全文翻译。统计功能只针对文本标注隔行对照部分内容,忽略意译行和全文翻译部分的文字,例如下面图书中常见的两种材料格式:三行和两行对照格式。


不管是三行还是两行,民族语言词条的统计以倒数第二行为准,对照汉语和语法标记以倒数第一行为准;尤其是在以汉语为目标词条统计时,要忽略意译行和篇翻译文本,更不能把标注文本之外的内容统计进来。这样便于使用者准确了解标注文本的实际情况,对目标语言的理解和把握更加精准。统计数据能从整体上了解一门语言的情况。隔行对照文本的特点是对真实口语文本的语法范畴和语法特征进行标记,在一定的文本数量的范围内,标记符号的数量能够反映出该语言的语法大概情况。《中国民族语言语法标注文本》20本书的标注文本数量多少不一,但大体保持在300页左右,词的总数量与语法标记的比例关系可以揭示几种事实,一是这种语言中语法范畴和语法特征的丰富程度,但是需要读者客观看待,因为每一本书的作者对语法特征的分析粒度也反应在语法标记的数量上;二是可以反映每一种语法标记在该语言中的分布状况,有些标记用得多,大体能说明该种语法现象普遍;有些标记用得少,大体能说明该种语法现象稀疏。下面以林幼菁《嘉戎语卓克基话语法标注文本》为例来分析。作者在书的前面列示了50个缩略标记符号。其中1、2、3表示第一、二、三人称,实际上在文本中出现时,1、2、3总是和表示单数、复数的SG和PL共现,因此在统计分析时,以1SG、1PL、2SG、2PL、3SG、3PL为统计对象。该书的语法标记符号统计基本情况如表1所示。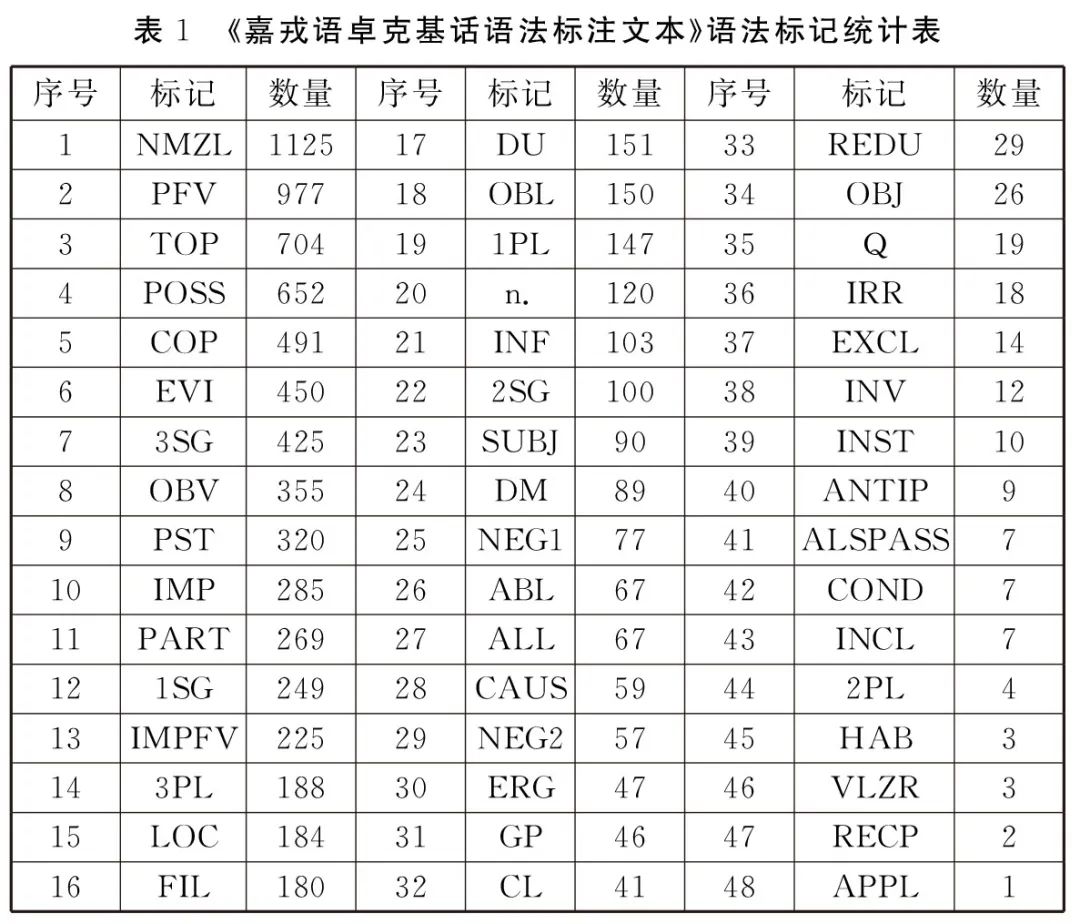
注释:作者提供的缩略表中有N(名词前缀),V1(动词第一词干)、V2(动词第二词干)标记在标注文本中没有统计到。从表1可以看出,嘉戎语卓克基话在文本中出现的语法范畴和语法特征的总体情况,数量排在前五的语法标记分别是:NMZL(名词化)、PFV(完整体)、TOP(话题)、POSS(领属)、COP(系词)。排在后五的语法标记分别是:2PL(第二人称复数)、HAB(习惯体)、VLZR(动词化标记)、RECP(互相)、APPL(应用标记)。再看看徐世璇的《土家语语法标注文本》,作者提供的语法标记符号23个,与嘉戎语卓克基话相比,数量上少了一半,表2是土语家语语法标记统计情况。排在前五的语法标记分别是:ASPP(体助词)、STRP(结构助词)、TOP(话题语气词)、3sg(第三人称单数)、CASP(格助词),排在后五位的分别是:HYPC(假设连词)、CAUC(因果连词)、COOC(并列连词)、IMPM(祈使语气)、1pl(第一人称复数)。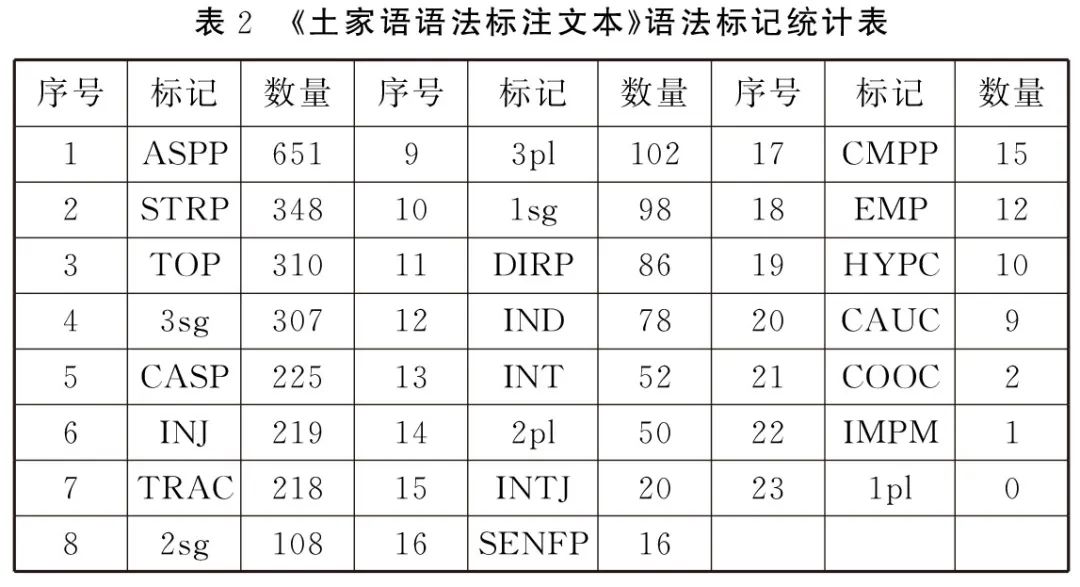
从表2的语法标记符号体系和统计数据可以初步了解到土家语与嘉戎语的语法类型差别较大,不论从语法标记的丰富程度还是不同类型的语法标记的使用频次,都表现出较大的差异性。通过比较土家语与嘉戎语两种语言的语法标记符号,我们可以发现,除了人称标记基本相同之外,只有TOP(话题标记)是共有的。一方面说明语言类型的差异,但另一方面也能反映出不同作者在进行文本标注时,对某些相同、相似语法现象的认识和看法不一致。因此,选择语法标记也就存在差别,这说明了我国民族语言的语法特征丰富,也说明在民族语言语法标记选用的一致性方面还需要做很多工作。我们对20本书的共用语法标记符号提取时,难以找到某一语法标记在20种语言和方言中共用的实例。一些比较常见的语法特征标记在某几种语言中是共有的。语法标记PFV(完整体)、LOC(位格)、ABL(从格)、ALL(向格)、COP(系词)、DAT(与格)出现的情况如图2所示。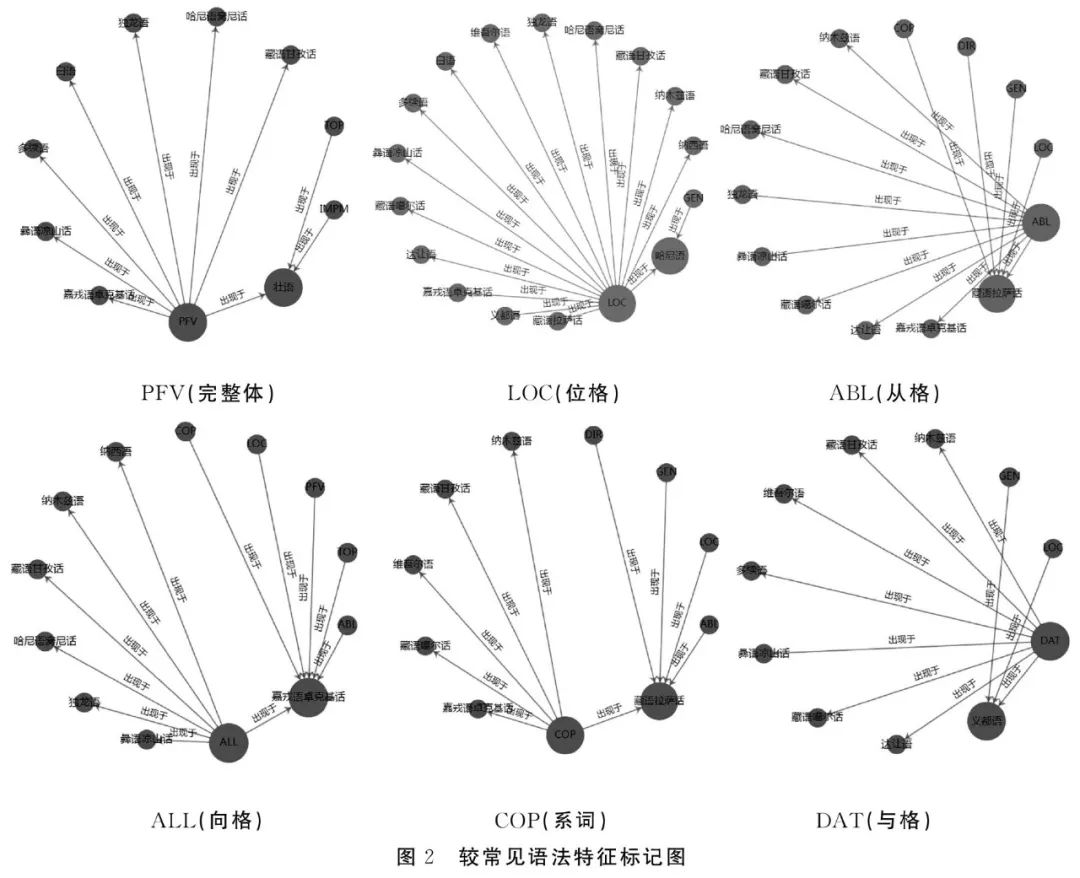
从这些关系图可以清楚看到,不同语言中的相同语法标记,这有利于揭示语言之间的共性特征,如果在统一规范的标注前提下,有一定规模语料的支持,可以为语言之间的系属关系研究提供新材料和新视角。当然本文主要讨论这种研究手段和方法,我们将另文深入讨论一些语法特征的共性和语言关系亲疏问题。总之,基于大规模语法标注文本,借助语料库、计算语言学的方法理论和数字人文技术,可以为中国语言学界提供丰富多样的中国民族语言材料,通过知识关联和可视化方法为大众提供民族语言基础知识,也为中国民族语言文化知识的普及传播奠定良好的基础,从这一点看,大规模隔行对照文本数据库构建已经体现出其重要的价值和意义。
《中国民族语言语法标注文本》丛书出版以来,学界对丛书的评价很高,例如刘丹青(2022)。但对丛书更多的意见和建议是“难以查询”。当然,这正是本项目拟解决的主要问题。针对带标注和注释的隔行对照化文本的对齐显示,虽然可以采用不同检索方式,本文采用的全文检索引擎原理方案同时考虑了用户对原著的信赖,同时也能提供上下文语境浏览功能。此外,以下5个方面也是本项目真正价值所在。第一,可检索性。即克服纸质文本资源应用上的固化和不方便。第二,强功能性。纸质文本是散装形式,每部书之间虽有共性却难以共用,而本项目可使所有专著资源关联起来,以前很多无法开展的工作都可以实现。例如可以通过检索趋向特征发现各种语言的趋向形式,形态关系,甚至渊源关系。第三,时效性。在线电子检索系统彻底摈弃逐页查看文本内容方式,用户可在短时间快速查看检索结果,大幅提高效率。第四,可扩展性。本套丛书目前仅出版了20部,相对上百种中国少数民族语言,还有极大的扩充空间。我们相信,采用在线检索方式有可能建立一种新的资源积累范式,加速中国(民族)语言文本资源的积累。第五,学术深度发展。本项目的成功一定会在某种程度上推动中国语言学的发展,即所谓大规模真实文本资源基础上的深度研究。
小语种低资源民族语言是语言学资源中很独特的一个类型,值得学术界细心呵护,精心培植,使其成为赓续中华文明和铸牢中华民族共同体意识的重要一环。(注:文章公众号推文中的参考文献及注释省略,详见纸刊)文章刊于《云南师范大学学报》
(哲学社会科学版)
2023年第6期

范俊军 沐华|我国低资源语言大规模数据建构及语言田野实践的数据转向
李春风|新国情背景下语言国情调查的系统观念
黄行|《世界民族语言》涉及中国语言国情的指标数据分析

云南师范大学学报(哲学社会科学版)不收取任何形式的审稿费、版面费。
云南师范大学学报(哲学社会科学版)唯一投稿途径为云南师范大学官网学报编辑部:
https://xbbjb.ynnu.edu.cn/CN/ynnu/home.shtml。
