:文本、语料资源和WordNet汇总")
- 最简单的是孤立的文本集合
- 按照文本等标签分类组成结构,如:布朗语料库
- 分类不严格,会重叠的语料库,如:路透社语料库
- 随时间/语言用法改变的语料库 ,如:就职演说库
注意 返回类似text1的Text对象
古藤堡语料库
包含36000本电子书,可以在这里下载
网络&&聊天体
网络text主要是非正式文学,论坛交流,剧本,评论等。聊天文本是根据聊天室划分的(文件名包括 日期、聊天室、帖子数量),被划分为15个大文件。
布朗语料库
百万词级语料库,没啥好说的。按照文本分类,如新闻、社论等。
因为这个语料库是研究文本间系统性差异的资源,所以可以来比较一下不同文本中情态动词的用法。
路透社语料库
新闻文档,分为“训练”和“测试”两组。便于及其进行训练和测试。命名就是'test/number'和'training/number'
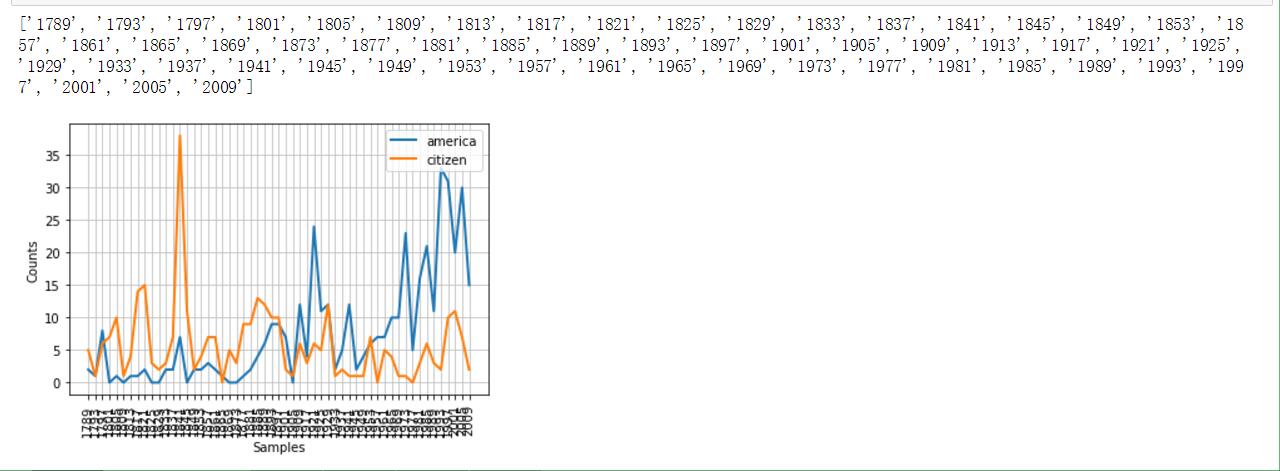
就职演说语料库
感觉这算是美国特色吧。因为命名采用'year-name.txt'的格式,我们可以提取出来时间维度,并且做个折线图来统计特定词汇的出现频率(不同年代中)
感受一下效果图(附截图)
如果想操作自己的语料库,并且使用之前的方法,那么,需要 函数来载入他们,这个函数参数有两个,第一个是根目录,第二个是子文件(可以使用正则表达式进行匹配)
词典:包括词性和注释信息。
stopwords即是,遗憾的是没有中文停用词
名字词典
就两部分组成,男性和女性的英文名字。这里我们研究一下最后一个名字最后一个字母和性别的关系
(附截图)

发音词典
这个更神奇,竟然是为了发音合成准备的。以后通读这本书后,也想想怎么迁移到中文上。
引入 后,我们可以得到它音素的长度,由此可以找到押韵的词语。
在因素表中,我们会发现数字:1,2,0。分别代表着:主重音、次重音、无重音。 这里我们可以定义一个function,找到具有特定重音模式的词汇。
最后必须说一下这个字典。WordNet是由Princeton 大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典。它不是光把单词以字母顺序排列,而且按照单词的意义组成一个“单词的网络”。
引入和同义词
motorcar和automobile是同义词,可以借助wordnet来研究。
结果是:[Synset('car.n.01')]。说明motorcar 只有一个 可能的含义。car.n.01被称为“同义 词集 ”。我们可以通过 来查看当前同义词集的其他词 (car这个单词就有很多个同义词集了) 。 和 可以分别查看定义和例子(但是Python3里面不可以。) 而类似car.n.01.car这样的处于下一级的称之为词条。 对于词条级别的obj,可以看下面的操作。
上位词、下位词、反义词
上位词(hypernym),指概念上外延更广的主题词。 例如:”花”是”鲜花”的上位词,”植物”是”花”的上位词,”音乐”是”mp3”的上位词。反过来就是下位词了。
上位词和下位词通过 和 来访问。
反义词就通过 来访问
其他词集关系
之前是从上->到下,或者反过来。更重要的是从整体->局部,或者反过来。如大树和树冠、树干的关系,这些是 。而大树集合就成了森林, 。而树的实质是心材和边材组成,即。
当两个单词有相同的上位词(在词树中寻找),而若上位词恰好属于较低层,那么它们会有一定密切联系。
当然,类似于树的结构中总是有神的,可以通过 来查看一个synset的最小深度。基于这些,我们可以在0-1的范围内返回相似度。对于上面的代码,查看相似度:。
以上就是本篇文章【NLTK学习笔记(二):文本、语料资源和WordNet汇总】的全部内容了,欢迎阅览 ! 文章地址:http://yybeili.xhstdz.com/news/4630.html 栏目首页 相关文章 动态 同类文章 热门文章 网站地图 返回首页 物流园资讯移动站 http://yybeili.xhstdz.com/mobile/ , 查看更多